

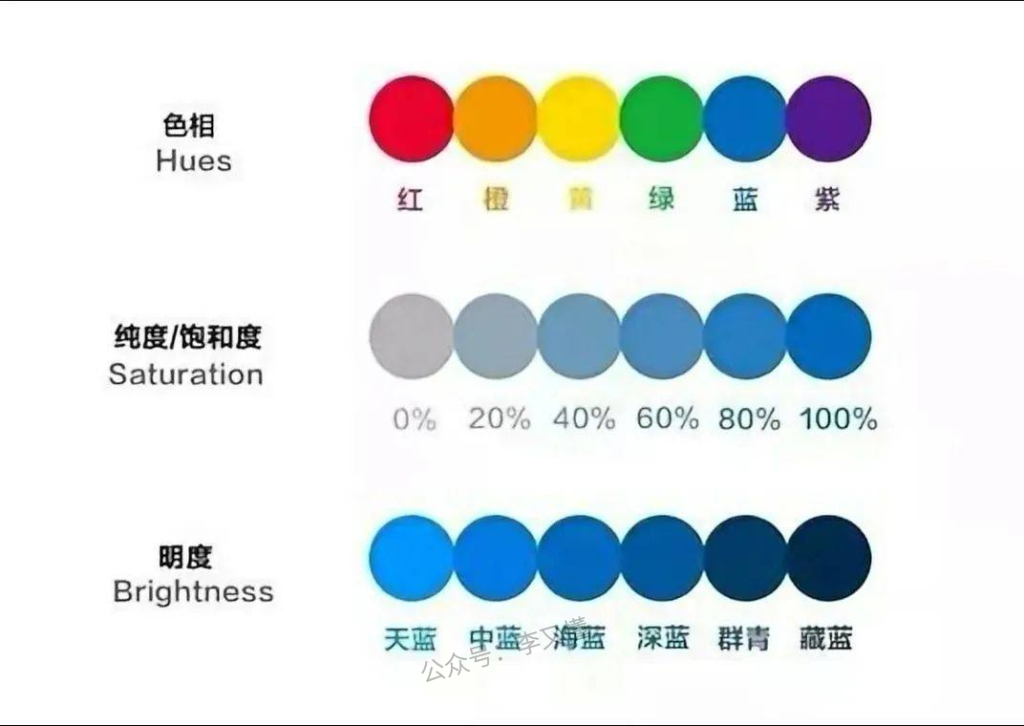
大语言模型是有上下文的限制的,专业术语是Token。
有时候看一些偏技术的文章,一些模型后面带着8k、32k,就是指这个大语言模型能够处理的Token的数量,简单理解一个Token是一个单词或者中文字,超过这个范围,造成上下文的信息丢失,大语言模型的反应可能和原始的提问不相关了。
Token 可以被理解为文本中的最小单位。在语言模型中,每一个Token约可以写1个英文字;中文则只能写0.5个字,这些字数会根据不同的文案而变动。根据《OpenAI》的建议,可以把每个Token看成i个带有4个字幕的英文单词,每个Token约可以写出75字的英文文章。
GPT-3语言模型:每词输出最高上限为2049个Token,大约可以写出1000字的中文文章、1720字的英文文章
GPT-4语言模型:每词输出最高上限为32768个Token,约是16056个中文字、25000个英文字
因为Token的长度有限,不要让GPT随意发挥,在内容比较多的情况,好好设计拆分一下。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
THE END



暂无评论内容